

L’entreprise data-driven
Vieux de quelques années et considéré parfois comme un buzzword, le concept d’entreprise data-driven a pris tout son sens suite à la crise sanitaire que le monde vient de traverser. Une entreprise est dite data-driven lorsque la donnée pilote ses actions et ses prises de décisions. L’analyse des données en continue permet à l’entreprise de répondre par une prise de décision adaptée et très souvent automatisée. L’adaptabilité aux changements est un des avantages concurrentiels que possède les entreprises ayant une maturité data plus avancée. [1]
Aujourd’hui nous pouvons affirmer que la gouvernance et analyse de données, appelée en anglais Data & Analytics (D&A), est un élément de différenciation et de performance pour les entreprises. Une conviction règne sur le marché, celle de la création de valeur à partir de la donnée.
Les cabinets d’analyse tels que Forrester [2] et Gartner [3] se sont déjà emparés du sujet et affirment que la fonction D&A doit être un contributeur clé au développement et à l’exécution de la stratégie d’entreprise en fournissant des informations sur des domaines essentiels, tels que les employés et les clients, les opportunités de marché non satisfaites, les tendances émergentes dans l’environnement externe, etc. [4]. À titre d’exemple, le cabinet Gartner prédit que :
« D’ici 2025, 70 % des entreprises qui surpasseront leurs concurrents sur les mesures financières clés indiqueront également qu’elles sont centrées sur la D&A » [1]
Dans la même étude, le cabinet Gartner, nous apprend que l’entreprise data-driven de demain pourra tirer à son avantage l’adaptabilité aux changements, l’optimisation opérationnelle et son intégration à de nouveaux outils.
Ces éléments traduisent bien l’intérêt des entreprises à devenir data-driven, mais quelles sont les vecteurs de transformation pour y parvenir ?
La donnée comme levier de création de valeur
Les entreprises sont confrontées à une forte augmentation du volume des données, ce phénomène entraîne de nouvelles complexités qui nécessitent un changement de paradigme dans le traitement et l’analyse de ces données. A son échelle, l’être humain n’est plus capable de gérer cette surcharge d’informations ainsi de nouvelles technologies et outils doivent être déployés.
Le sujet de cet article n’étant pas de lister l’ensemble des technologies d’analyse de données nous nous concentrerons sur un exemple central l’Intelligence Artificielle (IA) et plus particulièrement d’une de ses sous-branche le Machine Learning (ML) [5].
Les cas d’usages du Machine Learning sont aujourd’hui bien développés et variés à titre d’exemple on peut citer :
- L’analyse prédictive, pour de la maintenance prédictive, le calcul d’un risque ou l’identification d’opportunité sur le marché [6]
- La détection d’anomalies, pour la détection de fraude, de cyberattaque ou de défaut de fabrication [7]
- L’analyse de flux, pour optimiser le flux énergétique, informatique ou automobile [8]
Les nombreux usages et avantages de cette technologie ont poussé les entreprises a triplé l’utilisation de l’IA au cours des deux dernières années. Ce changement drastique oblige les leaders IT à réévaluer leurs infrastructures principales pour intégrer par exemple des plateformes d’orchestration de l’IA permettant d’accélérer et de pérenniser l’opérationnalisation de l’IA [9]. Intégrer l’IA dans sa stratégie de transformation est un marqueur concurrentiel fort.
L’adoption massive de l’IA et plus particulièrement du ML par les entreprises peut s’expliquer par deux éléments concordants, une confiance importante à travers le marché et une recherche active.
En effet, dans un sondage, Gartner révèle que 80% des leaders data sont convaincus que 100% des prises de décisions sont automatisables [10]. En parallèle de nouvelles technologies innovantes font leur apparition pour dépasser les limites actuelles de l’IA. Pour les plus curieux d’entre vous voici quelques exemples de ces nouvelles technologies :
- L’active metadata [11], c’est-à-dire l’utilisation du ML sur les métadonnées permettant une amélioration automatique des données (nettoyage, correction, smart discovery) et un gain de temps opérationnel important
- L’hyperautomatisation [12], désignant le mélange de l’IA avec des technologies d’automatisation comme la RPA pour automatiser les prises de décisions les plus complexes
- Le FedML [13], ou ML dans un cadre SMPC [14] pour entraîner un modèle sur une base de données distribuée et éviter ainsi les mouvements de donnée
Les limites de l’approche techno-centric
Les entreprises data-driven semble pouvoir se démarquer de leurs concurrents. Il est donc naturel de se demander pourquoi les entreprises n’ont pas toutes déjà pris ce virage. Nous avons observé que malgré un intérêt réel pour cette transformation, elle n’est pas facile à opérer et demande beaucoup d’agilité. Selon l’étude Gartner citée en introduction, la plupart des tentatives initiées par les entreprises en vue de construire leur stratégie data ont échoué. C’est une conséquence d’une approche uniquement techno-centré et sans mesure de l’impact business. Pour cela, il est essentiel de prendre la mesure de la valeur de la donnée pour les corps de métier la manipulant.
En reprenant notre exemple précédent, si l’IA est une solution pleine de promesse, il faut néanmoins prendre en considération certaines barrières pouvant ralentir sa démocratisation dans l’entreprise.
Ces barrières peuvent être externes à l’entreprise comme par exemples les aspects légaux (réglementation RGPD [15]), sécuritaires et éthiques de l’IA. Pour en savoir plus nous vous invitons à lire l’article suivant : Une Intelligence Artificielle 100% éthique peut-elle exister ?
Ses barrières peuvent être également internes, nous observons chez nos clients une difficulté opérationnelle à passer du POC (Proof Of Concept) à l’industrialisation des cas d’usages autour du ML. Les causes peuvent être multiples : la non-proximité entre l’IT et les métiers, données de mauvaise qualité, manque d’outillage pour le passage en production, etc. [16] En ce sens nous accompagnons nos clients dans l’organisation et la mise en œuvre de leur filière data. Notre vision globale dans ce domaine nous permet d’assister nos clients de façon horizontale. Cela passe par la réalisation d’atelier d’acculturation data jusqu’à la mise en place d’une nouvelle stratégie de data gouvernance.
Ces difficultés peuvent survenir lorsqu’une entreprise intègre de nouvelles technologies à sa stratégie data. L’objectif étant de rester concurrentielle en faisant évoluer son analyse et sa gouvernance de données. Par exemple, l’approche Multi-Cloud [17] augmente la difficulté de gouvernance et de sécurisation des données en rendant l’environnement toujours plus distribuée.
En résumé, dans un monde où la donnée est toujours plus volumineuse, distribuée et régulée, l’analyse des données n’est que la partie émergée de l’iceberg. Nous sommes face à un marché de la data en pleine émulation et porteur de promesse qui doit faire face à des enjeux importants de management, de gouvernance et de sécurité des données. Pour que ce marché atteigne son plein potentiel, il est essentiel que les entreprises répondent à ces enjeux en cadrant au mieux leurs leviers d’action.
Mise en place d’une Data Gouvernance
Au sein du cabinet Wavestone, nous avons la conviction qu’un axe majeur de transformation est la mise en place d’une organisation adaptée. Toute démarche visant à établir une stratégie data et une data gouvernance efficace, commence par une évaluation de la maturité [18] de l’entreprise sur ce sujet. Un élément fondateur de cette maturité est notamment l’existence dans l’organisation de rôles dédiés aux différentes tâches relatives à la gouvernance des données : ownership (Chief Data Officer), qualité (Data Quality Champion), sécurité (Data Protection Officer), etc.
Les noms et les qualifications de ces métiers peuvent évoluer d’une organisation à l’autre, l’important est de bien structurer les rôles de chacun, cela offrira une stratégie data compétitive. Cependant, il faut souligner qu’il n’existe pas un seul modèle type de gouvernance de données. Même si les missions de ces métiers ont tendance à se ressembler d’une organisation à l’autre, il faut contextualiser le modèle mis en place et répondre aux besoins de chaque organisation. Par exemple, un Data Mesh [19] est une solution qui n’est pas forcément adaptée à toutes les organisations. Il s’agit donc de s’adapter aux bonnes pratiques pour établir les fondements de votre structure.
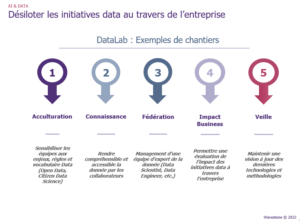
Une fois cette gouvernance mise en place, il sera essentiel d’associer un outillage adapté au niveau de maturité de l’entreprise (dictionnaire de la donnée pour un aspect connaissance par exemple) et d’intégrer une équipe opérationnelle pour traiter les sujets liés à la donnée, appelé parfois DataLab. Cette équipe pourra être centrale ou distribuée au sein des différents domaines de l’organisation. Cependant, il ne faut pas perdre de vue son rôle principal qui sera de désiloter les initiatives data au travers de l’entreprise, en les centralisant. En partant de ce postulat, l’équipe DataLab sera l’élément central de la stratégie mise en œuvre par ce même pôle. Il s’agira de traiter les cas d’usage prioritaires pour l’organisation, c’est-à-dire ceux avec un fort impact business et un faible risque, pour démontrer la pertinence de la démarche. Suivant les niveaux de maturité actuels et visés de l’entreprise, nous vous proposons ci-dessous différentes missions pouvant être portées par l’équipe DataLab.
Les problématiques de l’entreprise data-driven de demain
Une bonne stratégie data-driven s’appuie donc sur l’évaluation objective de son organisation, la refonte des métiers data et la maîtrise de nouvelles technologies. Il devient donc essentiel de former et sensibiliser ses équipes sur les notions data et tous les concepts qui y sont reliés. Les technologies de pointe se démocratisant toujours plus dans notre quotidien la donnée et son analyse sera demain l’affaire de tous, c’est ce qu’on appelle le Citizen IT [20]. En cela, le cabinet Wavestone s’est forgé ses propres convictions sur ces sujets et ces problématiques en devenir. L’évolution accompagne l’émergence d’enjeux nouveaux, nous en avons cité quelques-uns au cours de cet article.
Il nous paraît important d’évoquer un enjeu que nous n’avons jusqu’ici pas abordé, en effet ces progrès techniques entraineront avec eux une forte augmentation de notre impact carbone. En cela, des solutions visant à diminuer notre impact environnemental voient le jour, grâce au travail commun des chercheurs. Il ne s’agit plus d’installer des data centers dans des zones très froides, on voit désormais apparaître de nouvelles solutions. Par exemple, l’immersion des data centers dans l’huile, qui permet de diminuer la consommation d’eau et d’électricité. Il existe bien d’autres méthodes, plus innovantes les unes que les autres, parfaitement exposées dans l’article « Premières initiatives permettant de réduire l’impact environnemental des data centers ». Afin que les nouvelles technologies de gouvernance et d’analyse de données se développent sainement, il devient nécessaire de mesurer et de se prémunir de l’impact que celles-ci auront sur notre climat.
Bibliographie
[1] Predicts 2022: Data and Analytics Strategies Build Trust and Accelerate Decision Making, Gartner
[2] https://www.ibm.com/downloads/cas/AMRY7DYX, Forrester & IBM
[3] Over 100 Data and Analytics Predictions Through 2025, Gartner
[4] https://hbr.org/2017/06/how-to-integrate-data-and-analytics-into-every-part-of-your-organization, Harvard Business Review
[5] https://datascientest.com/machine-learning-tout-savoir, datascientest
[6] https://www.journaldunet.fr/web-tech/guide-de-l-intelligence-artificielle/1501305-analyse-predictive-definition-algorithme-et-cas-d-usage/, Journal du Net
[7] https://www.tibco.com/fr/reference-center/what-is-anomaly-detection, Tibco
[8] https://wintics.com/, Wintics
[9] IA en entreprise : le guide ultime pour exploiter la technologie, Intelligence-Artificielle.com
[10] Predicts 2022: Artificial Intelligence Core Technologies, Gartner
[11] https://towardsdatascience.com/what-is-active-metadata-and-why-does-it-matter-add3408c228, TDS
[12] Qu’est-ce que l’hyperautomatisation, ProcessMaker
[13] FedML short overview, FedML
[14] What is Secure Multi-Party Computation?, Medium
[15] Comprendre le RGPD, CNIL
[16] Donnée Wavestone
[17] Quels sont les avantages du Multi-Cloud, Oracle
[18] Donnée Wavestone
[19] Data Mesh : Définition, importance, applications, DataScientest
[20] Citizen Developer, Gartner

