

Rappel sur les notions de Machine Learning
Machine learning, deep learning, IA, cela fait maintenant quelques années que ces mots sont sur toutes les lèvres. Cet engouement pour les data sciences fait suite à l’explosion de la quantité de donnée produite. En effet, on estime que « 90% des données mondiales ont été créées ces deux dernières années » [1].
L’apprentissage automatique ou machine learning est un mode de programmation qui permet à un système informatique « d’apprendre » à résoudre un problème sans programmation explicite sur ce dernier en se basant notamment sur de l’optimisation statistique.
Il existe différents types de machine learning, tel que l’apprentissage supervisé où l’algorithme utilise des données labélisées pour apprendre à résoudre un problème. Par exemple, pour un ensemble de photos représentant des chiens ou des chats, l’algorithme va passer en revue les données d’entrainement en adaptant ses paramètres pour reconnaitre la différence entre un chien et un chat. Il pourra ensuite proposer une estimation de classification quand une nouvelle photo non labélisée lui sera présentée.
Il existe aussi l’apprentissage non supervisé qui quant à lui n’utilise pas de données labélisées mais a pour but d’identifier des patterns ou schémas dans et entre des données.
Cependant cela n’est que la partie émergée de l’iceberg, la partie la plus importante est celle d’analyse et de traitement des données. Sans données propres et utilisables, un modèle de ML ne saurait être performant.
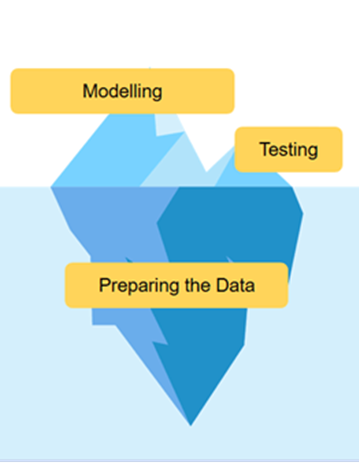
Les limites du Machine Learning
L’engouement pour le ML et les data science s’est développé dans de nombreuses entreprises, où de nombreux projets ont pu voir le jour. Cependant ces projets se sont vite heurtés à certains problèmes.
Le passage en production est souvent un moment critique dans le cycle de vie d’un projet ML. On estime que « Environ 20 à 30 % des projets menés dans les entreprises sont encore bloqués dans cette phase préalable et ne parviennent pas à arriver jusqu’à l’étape de l’industrialisation » [1]
En effet, l’élaboration d’un modèle de machine learning est un travail exploratoire qui n’aboutit pas toujours. Et une fois un modèle suffisamment performant obtenu, on peut se heurter à des problèmes de passage à l’échelle, ou comment industrialiser le modèle, le sécuriser, le rendre compatible avec l’environnement de production.
Une fois le modèle mis en production, il faut le maintenir. En effet, des problèmes de dérive peuvent apparaitre avec le temps et les nouvelles données entrantes, ce qui entraine des pertes de performance du modèle. Or une fois en production, le modèle est dans les mains du Data Engineer et le manque de communication avec les équipes de Data Scientists peut rapidement poser des problèmes si personne n’a de vue sur le travail de l’autre.
L’arrivée du MLOPS
Afin de maintenir et déployer des modèles de machine learning en production de manière fiable et efficace, un ensemble de bonnes pratiques a été pensé, ce qui a permis la naissance du MLOps. Cette appellation se décompose en deux termes bien connus et maitrisés aujourd’hui, à savoir le ML (Machine learning) et l’Ops (ensemble de bonnes pratiques opérationnelles de développement continu). Ainsi le MLOps se retrouve au croisement de trois métiers : le data scientist, le data analyst et le data engineer.
On cherche à travers cette approche à améliorer la qualité des modèles de production.
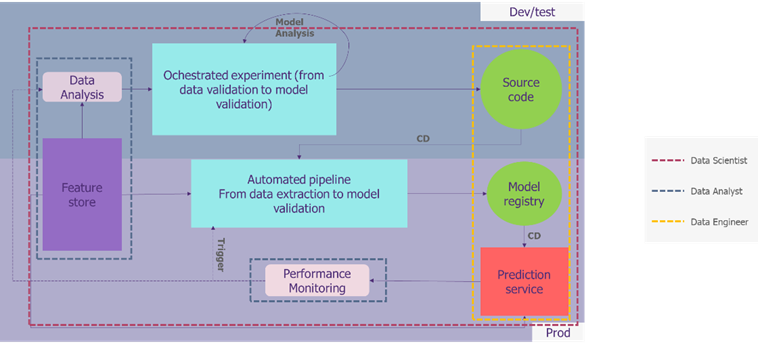
Le MLOps s’applique aujourd’hui de la mise en place d’un feature store (en violet) à la transformation des données brutes en modèle de machine learning (en bleu) tout en permettant une gestion du code et des modèles (en vert) ainsi qu’une analyse des performances et des données en continu (en gris).
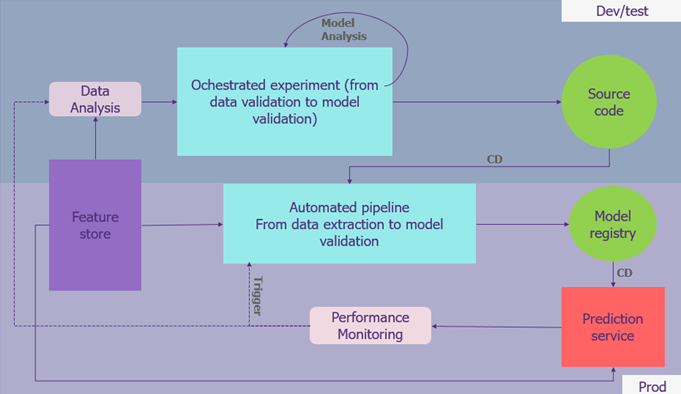
Qu’est-ce que le MLOPS ?
Pipeline principale
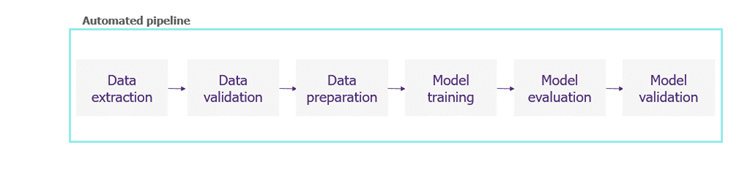
La partie centrale d’un projet de data science souhaitant mettre en place les méthodes du MLOPS est constituée du pipeline de données. Ce pipeline a pour principal objectif de transformer les données brutes en modèle de machine learning opérationnel et prêt à être déployé.
Il doit donc être capable de :
- Récupérer les données brutes à exploiter,
- Vérifier la qualité des données en testant leur structure et si les valeurs qu’elles contiennent sont cohérentes avec ce qui est attendu,
- Préparer les données,
- Entrainer le modèle,
- Évaluer le modèle sur un jeu de test en même temps que l’entrainement,
- Valider le modèle sur des données de validation et en comparant ses performances aux modèles de références,
Ce pipeline sera utilisé lors des phases de développement et d’exploration par les data scientists afin d’automatiser leur travail et de créer de façon plus efficace et rapide des modèles de machine learning et de les standardiser.
Le pipeline est aussi présent sur l’application en production. Celui-ci permet de préparer nos modèles qui seront utilisés en production mais aussi de les mettre à jour en continu. En effet, lorsque les performances du modèle faiblissent, la partie monitoring de notre infrastructure permet d’enclencher le réentrainement du modèle grâce au pipeline.
Gestion du code et des modèles
Comme la plupart des projets IT, le code source de développement est stocké dans un repository afin d’effectuer du versioning, de travailler à plusieurs collaborateurs sur le même code et d’inclure de la documentation, des notes et autre.
Afin de garder une trace des différents modèles et de pouvoir les comparer simplement, ces derniers sont stockés dans un model registry. Un model registry est basiquement un repository utilisé pour stocker des modèles entrainés de machine learning. En plus des modèles en eux-mêmes, des métadonnées sont stockées telles que les données utilisées ainsi que les paramètres utilisés pour l’entrainement ou encore les métriques d’évaluation de ces derniers. Cela permet de rapidement comparer différents modèles et de ne pas perdre le fil des entrainements. Les solutions du marché les plus connues sont : MLFlow, Sage Maker and Neptune.
Un nouvel élément : Le feature Store
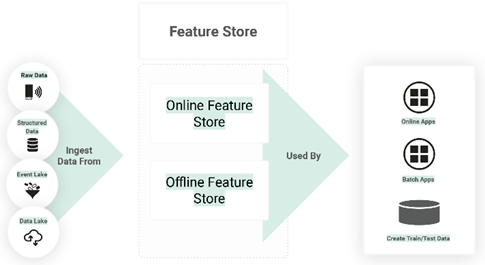
Le Feature Store pour l’apprentissage automatique est un service de calcul et de stockage de features qui permet d’enregistrer, de trouver et d’utiliser des caractéristiques à la fois dans le cadre de pipelines d’apprentissage automatique et d’applications en ligne pour l’inférence de modèles.
Les Feature Stores sont généralement nécessaires pour stocker à la fois de grands volumes de données sur les features et fournir un accès à faible latence aux features pour les applications en ligne.
Ils sont généralement mis en œuvre sous la forme d’un système à double base de données : un feature store en ligne à faible latence et une base de données SQL à grande échelle pour stocker de grands volumes de données.
Le feature store en ligne permet aux applications en ligne d’enrichir les vecteurs de caractéristiques avec des données de caractéristiques en temps quasi réel avant d’effectuer des demandes d’inférence. Le feature store hors ligne peut stocker de grands volumes de données de caractéristiques qui sont utilisées pour créer des données d’entraînement/de test pour le développement de modèles ou par des applications par lots pour la notation de modèles.
Le Feature Store résout les problèmes suivants dans les pipelines pour l’apprentissage automatique :
- Réutilisation des pipelines de fonctionnalités en partageant les fonctionnalités entre les équipes/projets ;
- Permet de servir des fonctionnalités à l’échelle et avec une faible latence ;
- Assure la cohérence des caractéristiques entre l’entrainement et le service, les caractéristiques sont conçues une fois et peuvent être mises en cache dans les magasins de caractéristiques en ligne et hors ligne ;
- Garantit l’exactitude ponctuelle des caractéristiques — lorsqu’une prédiction a été faite et qu’un résultat arrive plus tard, nous devons être en mesure d’interroger les valeurs des différentes caractéristiques à un moment donné dans le passé.
Monitoring des modèles et analyse de donnée
Lorsque le service de prédiction est en production, il peut apparaitre des problèmes de dérive ce qui peut entrainer des pertes de performance. Afin d’éviter cela, le MLOPS intègre une brique de performance monitoring qui surveille que la performance du modèle est toujours au-dessus d’un certain seuil et qui déclenche un réentrainement du modèle si les performances se dégradent. Cette boucle permet de s’assurer d’avoir un outil de prédiction satisfaisant en permanence.
De la même manière, les données de performance sont analysées pour effectuer de nouveaux tests et développements et toujours améliorer le service. [3]
Comment mener à bien un projet MLOps
Maintenant que nous avons saisi ce qui se cache derrière le terme MLOps, il est important de comprendre les prérequis nécessaires à la mise en place de ces bonnes pratiques.
Les prérequis à la mise en place de projet MLOPS
Le concept et la pratique du MLOps est relativement neuve sur le marché international et beaucoup d’entreprises n’ont pas une maturité suffisante sur certains aspects technologiques. La mise en place du MLOps se confronte donc à des problématiques concrètes importantes. Pour mener à bien un projet MLOps, il est important de correctement évaluer le niveau de maturité de l’entreprise sur ces différents points en se posant les bonnes questions :
Maturité sur l’utilisation et le stockage des données :
- L’entreprise possède-t-elle une plateforme data, un data hub ? Les données sont-elles propres ? Quels sont les modèles de données ? Quelle est la qualité des données ?
Maturité sur les processus agiles :
- L’entreprise est-elle mature sur les méthodes devOps ? Utilise-t-elle des outils de versioning/monitoring ? Si oui lesquels ? Utilise-t-elle des méthodes de gestion de projet agile ? (Scrum, découpage en sprint…)
Maturité en terme de Machine Learning/ deep learning:
- L’entreprise compte-t-elle des data Scientists ? Utilise-t-elle des outils de gestion de modèles ? Comment est effectué le pré-traitement des données (automatisé ou manuel) ? Il y-a-t-il des outils de monitoring des modèles ?
Pour aller plus loin : quelle est la maturité au niveau data engineer ?
- Il y a-t-il besoin de provisionner des infrastructures parfois gourmandes en compute/storage ? L’entreprise est-elle familière avec les outils de cloud computing ?
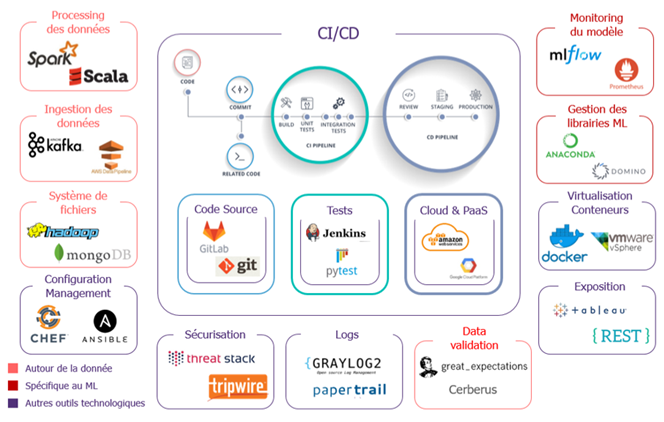
L’expertise nécessaire pour un projet de MLOPS
Un projet MLops est bien plus qu’un projet ML, de nombreuses compétences sont nécessaires pour mener à bien un tel projet.
- Des compétences en data engineering pour gérer les flux de données et leur hébergement
- Des compétences en data visualisation pour le monitoring des modèles et l’analyse des données
- Des compétences en machine learning pour l’entrainement des modèles la préparation des données et l’analyse de performance du modèle.
- Des compétences en analyse de données pour comprendre les données métier et les mettre en forme
Ainsi, généralement un projet MLOPS est géré par une équipe pluridisciplinaire comprenant au moins :
- Un data scientist
- Un data analyst
- Un data engineer
Conclusion
Le marché du MLOps est très prometteur et de plus en plus d’entreprise comprennent les enjeux et la nécessité de mettre en place ces bonnes pratiques. « Le marché du MLOps était estimé à 23,2 milliards de dollars en 2019 et devrait atteindre 126 milliards de dollars d’ici 2025 en raison de son adoption rapide » [4]
Ainsi, pour les entreprises souhaitant mettre en place de l’apprentissage automatique reproductible en production et de la maintenabilité à long terme, l’investissement en temps pour mettre en place une approche MLOps peut être élevé, mais les avantages sont considérables.
Références
[1] «https://ryax.tech/fr/comment-industrialiser-data-science/,» [En ligne]. Available: https://ryax.tech/fr/comment-industrialiser-data-science/.
[2] «https://blogs.iadb.org/conocimiento-abierto/en/how-ai-works-iceberg-model/,» [En ligne]. Available: https://blogs.iadb.org/conocimiento-abierto/en/how-ai-works-iceberg-model/.
[3] «https://www.phdata.io/blog/what-is-a-model-registry/,» [En ligne]. Available: https://www.phdata.io/blog/what-is-a-model-registry/.
[4] «« 2021 MLOps Platforms Vendor Analysis Report »».Neu.ro.

