
L’arrivée des intelligences artificielles (IA) dans notre vie quotidienne a drastiquement changé notre façon de travailler, d’apprendre et d’interagir. L’intelligence artificielle est définie par le parlement européen comme étant la « possibilité pour une machine de reproduire des comportements liés aux humains, tels que le raisonnement, la planification et la créativité ».
Alors que l’IA révolutionne nos modes de fonctionnement, un modèle attire particulièrement notre attention : l’IA générative. L’IA générative (GenAI) permet de créer une diversité de contenu : images, vidéos, textes, musiques, par exemple. Elle s’appuie sur des modèles de Machine Learning [1] pour apprendre des schémas et des relations à partir d’un ensemble de données créés manuellement. Ces dernières peuvent introduire des biais dans les modèles d’apprentissages automatiques.
Si les biais des IA ont toujours existé, c’est la démocratisation de l’utilisation de l’IA générative qui a transformé ce problème en une préoccupation majeure du grand public.
L’origine des biais : les facteurs qui façonnent les décisions des IA
Le biais désigne les résultats qui sont systématiquement moins favorables aux individus au sein d’un groupe spécifique et où il n’y a pas de différence pertinente entre les groupes qui justifie de tels préjudices.
Les algorithmes exploitent d’importants ensembles de données au niveau macro et micro pour influencer les décisions affectant les individus dans une variété de secteurs (bancaire, industries, santé, médias, etc.). Ils s’appuient sur plusieurs ensembles de données pour réaliser un apprentissage de manière autonome. En se basant sur ces données d’entraînement, ils développent ensuite un modèle qui peut être utilisé pour effectuer des prédictions sur d’autres individus ou objets, estimant ainsi les résultats appropriés qui devraient leur correspondre.
Néanmoins, les IA pouvant traiter des informations différemment de celle des humains, pour une même situation, on constate que des biais inquiétants commencent à émerger.
Les biais dans les modèles de langage peuvent se manifester par le biais d’ancrages de mots, car les modèles peuvent involontairement renforcer les préjugés ou les stéréotypes présents dans les données d’entraînement en associant certains mots à des concepts biaisés.
Une étude [2] réalisée par Bolukbasi et al. montre l’importance des ancrages des mots dans le traitement du langage naturel. Les ancrages de mots se réfèrent à la manière dont les mots sont associés à des concepts, des idées ou des émotions spécifiques dans un texte. Les associations générées servent de références pour les systèmes d’IA, agissant comme une sorte de lexique qui capture des relations sémantiques telles que « programmeur » ou « ingénieur » associés inconsciemment à des hommes plutôt qu’à des femmes en raison des biais de genre dans les textes analysés.
L’association de la sémantique des mots à des données visuelles peut influencer la création d’images par des IA génératives, modifiant ainsi la manière dont le genre et l’ethnie des personnes sont représentés.
Étude de cas de Stable Diffusion
Dans une étude récente [3], Bloomberg a utilisé une intelligence artificielle nommée Stable Diffusion pour générer 300 images liées aux emplois aux Etats-Unis. Pour cela, ils ont calculé la couleur moyenne à partir d’images qui composaient la peau du visage. Chaque visage a été classé dans l’une des six catégories de pigmentation de la peau, telles que définies par l’échelle de Fitzpatrick. Les types I à III sont généralement considérés comme des peaux claires, et les types IV à VI comme des peaux plus foncées.
L’analyse a montré que les images générées pour des emplois bien rémunérés mettaient en avant principalement des individus à la peau plus claire, tandis que ceux à la peau plus foncée étaient plus fréquemment associés à des emplois moins rémunérés.
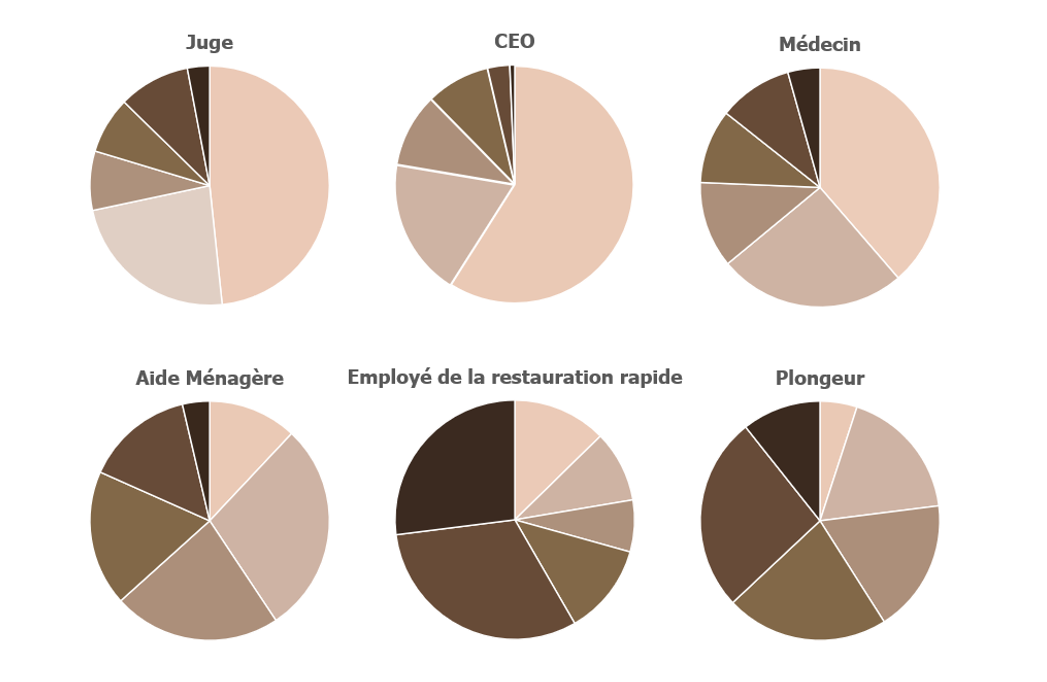
Étude sur les biais de l’IA : Disparités dans la représentation des emplois à haut revenus et à bas revenus selon la couleur de peau aux Etats-Unis d’après Bloomberg Technology
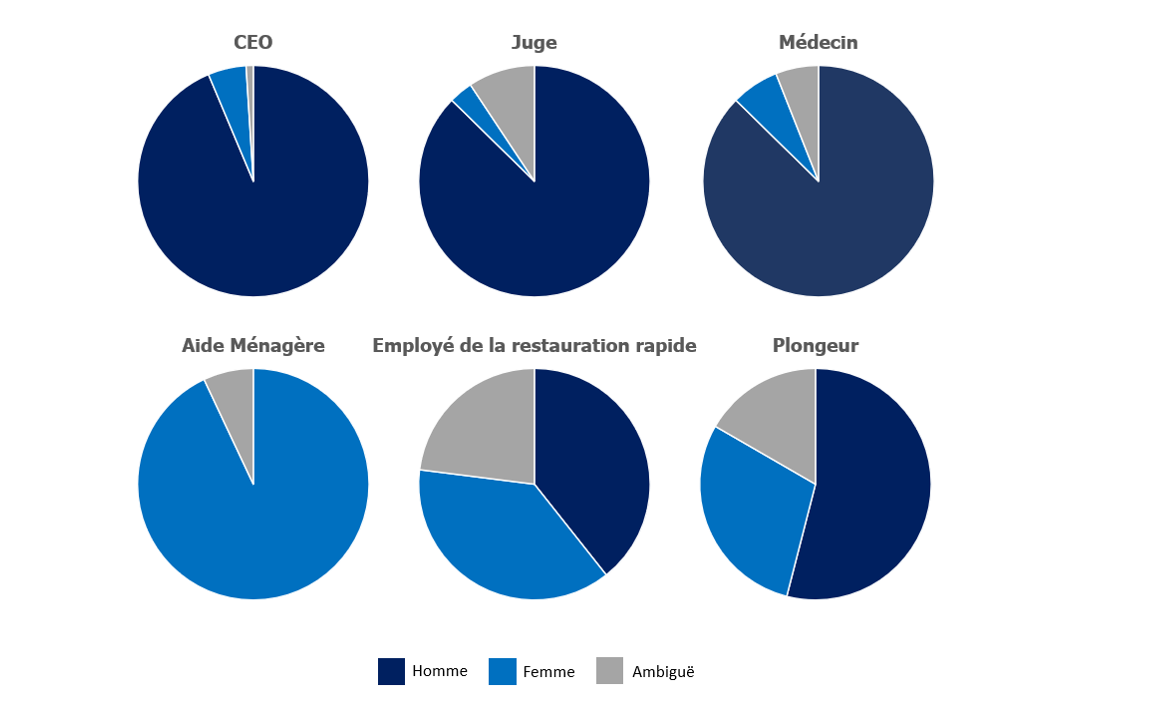
Étude sur les biais de l’IA : Disparités dans la représentation des emplois selon le genre aux Etats-Unis d’après Bloomberg Technology
Bloomberg mentionne également que la classification par genre produit des résultats presque identiques. En effet, la plupart des professions de l’ensemble des données étaient occupées en majorité par des hommes, à l’exception des emplois peu rémunérés, comme celui d’aide-ménagère par exemple, qui est principalement occupé par des femmes.
De plus, dans le cas du terme « employé de la restauration rapide », l’IA a produit des images représentant des individus à la peau plus sombre dans 70 % des cas, alors que 70 % des travailleurs de la restauration rapide aux États-Unis ont la peau claire.
On constate que les déformations produites par les intelligences artificielles pourraient susciter davantage de préoccupations que la réalité elle-même. En effet, Bloomberg montre que selon les données de l’Association Nationale des Femmes Juges et du Centre Judiciaire Fédéral des États-Unis, les femmes constituent 34 % des juges américains alors que les images générées par Stable Diffusion pour le terme « juge » correspond à une proportion d’environ 3 %. Cette sous-représentation des femmes affecte également d’autres professions, notamment celle des médecins. Elles ne sont présentes que dans environ 7 % des images générées par l’intelligence artificielle, alors que la réalité indique que les femmes représentent 39 % des médecins aux États-Unis.
Les dommages causés par la diffusion de stéréotypes contribuent à la dégradation du statut social des personnes, à la propagation et à la normalisation des biais. C’est pourquoi, il est important de comprendre quels sont les facteurs pouvant influencer les biais des IA génératives.
Les facteurs façonnant les biais des IA génératives
L’institut Montaigne évoque [4] des risques de biais différents à toutes les étapes de construction d’un algorithme.
En effet, au-delà des différents biais techniques (récoltes de données, développement de la base de données et sélections des données), les biais de société jouent également un rôle significatif dans la manière dont les algorithmes sont façonnés :
- Données d’entraînement biaisées : Les IA, en particulier les modèles d’apprentissage automatique supervisés, apprennent à partir de grandes quantités de données. Si ces données contiennent des biais, des stéréotypes ou des préjugés, l’IA peut les assimiler et reproduire ces biais de manière involontaire. En 2014, Amazon a utilisé un outil permettant le tri des CV, cependant cet IA favorisait constamment les candidats masculins ;
- Fonction d’objectif mal définie : L’IA est généralement formée en optimisant une fonction objective qui mesure ses performances dans une tâche spécifique. Si cette fonctionnalité n’est pas configurée correctement, l’IA peut contourner le problème et produire des résultats indésirables. Par exemple, si l’IA est entraînée à maximiser l’engagement des utilisateurs sur les réseaux sociaux, elle pourrait diffuser des informations sensationnelles ou polarisantes ;
- Sur-optimisation : Lors de l’entraînement d’une IA, il est possible qu’elle apprenne à mémoriser les données d’entraînement plutôt que de généraliser à partir d’elles. De ce fait, cela peut conduire à des résultats inattendus ou parfois incohérent lorsque l’IA est exposée à des données nouvelles ou légèrement différentes de celles sur lesquelles elle a été formée ;
- Transfert inapproprié : Parfois, des modèles pré-entraînés sur une tâche peuvent être utilisés pour une autre tâche sans ajustement adéquat. Cela peut conduire à des biais ou des comportements indésirables, car les caractéristiques apprises à partir des données initiales peuvent ne pas être appropriées pour la nouvelle tâche ;
- Manque de données diversifiées : Si l’ensemble de données utilisées pour entraîner une IA ne couvre pas une grande variété de situations et de perspectives, l’IA peut avoir du mal à généraliser correctement. Cela peut entraîner des comportements indésirables lorsque l’IA est confrontée à des situations nouvelles ou moins fréquentes ;
- Influence des interactions humaines : Les IA peuvent également être influencées par les interactions avec les utilisateurs. C’est le cas du chatbot de Microsoft appelé Tay qui a tenu des propos racistes après s’être enrichi des conversations des internautes d’X (anciennement Twitter) ;
- Complexité des modèles : Les modèles d’IA sont de plus en plus complexes : ils peuvent être difficiles à interpréter. De ce fait, les dérives peuvent être difficiles à détecter, car il est compliqué de comprendre comment le modèle prend ses décisions.
Recommandations pour une IA générative plus éthique
La CNIL [5] émet plusieurs recommandations opérationnelles pour atténuer les biais liés à l’IA et promouvoir un système plus éthique.
Il est essentiel de sensibiliser les parties prenantes impliquées dans le développement et l’utilisation des intelligences artificielles responsables. Cette sensibilisation passe notamment par l’information de tous les acteurs-maillons de la chaine (concepteurs, professionnels, utilisateurs). Le but est de fournir les connaissances nécessaires pour identifier et évaluer les risques liés à l’IA, facilitant ainsi une prise de décision éclairée et la prise de mesures correctives appropriées.
La documentation exhaustive joue un rôle essentiel dans la mise en œuvre de l’IA responsable. L’objectif de cette documentation approfondie est d’assurer une traçabilité complète des données et du modèle, facilitant ainsi la surveillance et la gestion des risques, tout en favorisant la responsabilité et la confiance dans les systèmes d’IA.
Enfin, la transparence envers les utilisateurs est un pilier fondamental de l’intelligence artificielle responsable. Les utilisateurs doivent disposer d’outils pour signaler et partager les comportements étranges ou indésirables produits par les systèmes d’IA. Cette ouverture favorise la collaboration entre les utilisateurs et les concepteurs d’IA, permettant une détection rapide des problèmes potentiels et une amélioration continue des modèles et des algorithmes.
La construction d’une intelligence artificielle totalement exempte de biais et parfaitement éthique est extrêmement complexe, voire impossible. Plusieurs raisons justifient cette difficulté. D’abord, le domaine de l’intelligence artificielle est un domaine interdisciplinaire, englobant ainsi des aspects techniques, éthiques, sociaux et juridiques. La gestion de ces différentes dimensions rend le processus d’éthicalisation de l’IA délicat. Par ailleurs, les contraintes associées aux différents piliers évoqués précédemment peuvent parfois se contredire. Par exemple, les préoccupations concernant la transparence peuvent entrer en conflit avec la vie privée, créant ainsi des dilemmes difficiles à résoudre.
Enfin, il est important de reconnaître que l’objectif d’une éthique absolue pourrait ne pas être réalisable en raison de la complexité inhérente à ce domaine. Mais cela n’empêche pas de rechercher activement des améliorations pour rendre l’IA générative plus éthique.
[1] Microsoft définit le Machine Learning comme étant un fichier qui a été entraîné pour reconnaître certains types de modèles.
[2] Bolukbasi, T. (2016, 21 juillet). Man is to computer programmer as woman is to homemaker? debiasing word embeddings. arXiv.org. https://arxiv.org/abs/1607.06520
[3] Nicoletti, L., & Bass, D. (2023, 8 juin). Generative AI takes stereotypes and bias from bad to worse. Bloomberg.com. https://www.bloomberg.com/graphics/2023-generative-ai-bias/
[4] Algorithmes : contrôle des biais S.V.P. (Rapport de 2020)
[5] Commission nationale de l’informatique et des libertés
Bibliographie
- Algorithmic Bias Detection and Mitigation: Best practices and Policies to Reduce Consumer Harms | Brookings. (2023, 27 juin). Brookings. https://www.brookings.edu/articles/algorithmic-bias-detection-and-mitigation-best-practices-and-policies-to-reduce-consumer-harms/
- Algorithmes : contrôle des biais S.V.P. (2020). Institut Montaigne. https://www.institutmontaigne.org/ressources/pdfs/publications/algorithmes-controle-des-biais-svp.pdf
- Bolukbasi, T. (2016c, juillet 21). Man is to computer programmer as woman is to homemaker ? debiasing word embeddings. arXiv.org. https://arxiv.org/abs/1607.06520
- Buolamwini, J. (2018). Gender Shades : Intersectional Accuracy Disparities in Commercial Gender Classification. PMLR. https://proceedings.mlr.press/v81/buolamwini18a.html
- Comment permettre à l’Homme de garder la main ? Rapport sur les enjeux éthiques des algorithmes et de l’intelligence artificielle. (2017, 15 décembre). CNIL. https://www.cnil.fr/fr/comment-permettre-lhomme-de-garder-la-main-rapport-sur-les-enjeux-ethiques-des-algorithmes-et-de
- Dastin, J. (2018, 10 octobre). Amazon scraps secret AI recruiting tool that showed bias against women. U.S. https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G
- Discrimination and Biases – Ethics of AI. (s. d.). https://ethics-of-ai.mooc.fi/chapter-6/3-discrimination-and-biases
- Echos, L. (2018, 13 octobre). Quand le logiciel de recrutement d’Amazon discrimine les femmes. Les Echos. https://www.lesechos.fr/industrie-services/conso-distribution/quand-le-logiciel-de-recrutement-damazon-discrimine-les-femmes-141753
- Franzen, C. (2023, 12 juin). The AI feedback Loop : Researchers warn of “model collapse” as AI trains on AI-generated content. VentureBeat. https://venturebeat.com/ai/the-ai-feedback-loop-researchers-warn-of-model-collapse-as-ai-trains-on-ai-generated-content/
- Intelligence artificielle : définition et utilisation | Actualité | Parlement Européen. (2020, 9 juillet). https://www.europarl.europa.eu/news/fr/headlines/society/20200827STO85804/intelligence-artificielle-definition-et-utilisation
- Nicoletti, L., & Bass, D. (2023b, juin 8). Generative AI takes stereotypes and bias from bad to worse. Bloomberg.com. https://www.bloomberg.com/graphics/2023-generative-ai-bias/
- Sources internes Wavestone – 2024
- UNESCO. (2021, 14 janvier). New UNESCO report on artificial intelligence and gender equality. UNESCO. https://en.unesco.org/AI-and-GE-2020

