

Lakehouse : la nouvelle architecture data qui réconcilie agilité et gouvernance
À l’heure où la donnée s’impose comme un actif stratégique vital et surtout avec l’explosion de l’intelligence artificielle ces dernières années, les entreprises sont confrontées à un dilemme technique majeur : comment stocker, analyser et gouverner des volumes toujours plus importants et variés, tout en gardant le contrôle sur la qualité, la sécurité et la performance ?
Depuis plusieurs années, le Data Warehouse garantit robustesse analytique, structuration et fiabilité, mais au prix d’une rigidité, d’un coût élevé et d’une faible capacité à gérer la diversité des formats et la volumétrie moderne. À l’inverse, le Data Lake a permis d’absorber l’explosion des données hétérogènes à moindre coût. Il a ouvert la voie à des cas d’usage variés, mais s’est heurté à des limites pour des usages métiers plus exigeants : absence de transactions, gouvernance lacunaire, difficultés d’évolution du schéma, performances parfois imprévisibles.
Architecture Lakehouse
C’est dans ce contexte qu’émerge l’architecture Lakehouse apparu courant 2010, qui allie les avantages des architectures précédentes. Le Lakehouse propose une plateforme unifiée où la donnée, qu’elle soit brute ou prête à l’usage, circule sans rupture ni duplication entre les usages. Il conserve la flexibilité de stockage et la scalabilité du Data Lake grâce a son stockage au sein d’un stockage, tout en apportant la fiabilité, les capacités analytiques et la gouvernance fine du Data Warehouse.
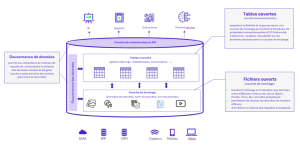
Concrètement, une architecture Lakehouse s’articule autour
- D’un socle de stockage objet cloud,
- D’une couche de tables ouvertes,
- D’un catalogue de métadonnées centralisé
Cette approche favorise l’agilité des pipelines de données, optimise les coûts et permet une gouvernance transversale à l’ensemble du cycle de vie de la donnée.
La force du Lakehouse ne repose donc pas sur une seule brique technologique, mais sur l’intégration intelligente de trois piliers complémentaires, qui garantissent interopérabilité, évolutivité et confiance. Pour comprendre en profondeur cette approche, plongeons dans les différents piliers de cette architecture.
Premier pilier : le format de fichier ouvert
Historiquement, les formats plats comme CSV ou JSON ont rapidement montré leurs limites pour l’analyse à grande échelle. Les formats en colonne, tels que Parquet, ORC ou, s’imposent aujourd’hui grâce à ce qu’il offre comme caractéristique
- Une performance en lecture/écriture nettement supérieure,
- Une compression avancée,
- Une interopérabilité naturelle avec les moteurs analytiques modernes (Spark, BigQuery, Athena…).
Parquet, en particulier, est devenu le standard de fait dans les architectures analytiques cloud. Cependant, les formats de fichiers ouverts seuls ne suffisent pas à combler toutes les lacunes des architectures précédentes, ce qui nous conduit au deuxième pilier essentiel : les tables ouvertes.
Deuxième pilier : la table ouverte
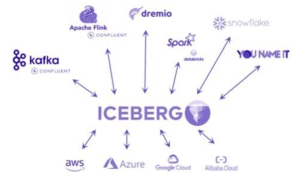
Au-dessus du stockage, les formats de table ouverts comme Delta Lake, Apache Iceberg ou Apache Hudi apportent les fonctionnalités essentielles qui faisaient défaut aux Data Lakes historiques : gestion des transactions ACID, time travel, évolution du schéma et mutations fiables. Delta Lake séduit par sa simplicité d’intégration dans l’écosystème Databricks, alors qu’Apache Iceberg prend une place croissante dans les architectures multicloud ou multimoteurs grâce à son indépendance. Plus qu’un choix de format, c’est désormais l’écosystème de gestion et de gouvernance qui prime : la convergence des fonctionnalités entre Iceberg et Delta Lake qui les rend interchangeables rend le choix de la brique technique moins structurant qu’il y a quelques années. Enfin, pour garantir une véritable gouvernance à l’échelle, le troisième pilier s’impose naturellement : la gouvernance rigoureuse des métadonnées.
Troisième pilier : la gouvernance des métadonnées
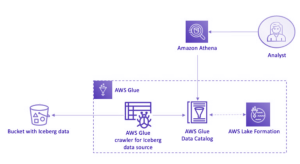
Enfin, la réussite d’un Lakehouse repose sur une gouvernance rigoureuse des métadonnées. Les catalogues centralisés (Unity Catalog, AWS Glue, Hive Metastore…) deviennent la pierre angulaire de l’architecture. Ils permettent d’orchestrer schémas, partitions, accès, audit et documentation, tout en assurant la cohérence et la sécurité des données à travers les usages et les outils. L’intégration native dans des plateformes comme Databricks ou Snowflake fluidifie encore davantage la gestion et la consommation de la donnée, tandis que la multiplicité des services côté AWS ou GCP complexifie parfois la mise en œuvre. Ainsi structurée autour de ces trois piliers complémentaires, l’architecture Lakehouse répond concrètement aux défis actuels et futurs de la gestion des données.
Conclusion
Pour conclure, l’architecture Lakehouse s’impose progressivement comme une réponse concrète aux défis de la donnée moderne : elle permet d’exploiter à grande échelle la richesse des informations issues de sources variées, sans sacrifier la gouvernance ni la performance. En combinant le meilleur des Data Lakes et des Data Warehouses autour de trois grands piliers, fichiers ouverts, tables ouvertes et métadonnées centralisées, le Lakehouse accompagne la transformation des entreprises vers des usages data toujours plus avancés, agiles et fiables.
À l’heure où l’écosystème technique s’enrichit comme avec le dernier Databricks Summit et l’annonce de la pleine compatibilité entre Unity Catalog et Iceberg et où la frontière entre stockage et analyse s’efface, cette approche unifiée apporte une vraie continuité : elle permet enfin d’allier maîtrise des coûts et gouvernance, tout en s’adaptant aux évolutions rapides des technologies cloud. À l’heure où les architectures Lakehouse s’appuient de plus en plus sur des catalogues unifiés pour garantir cohérence, sécurité et agilité, on peut se demander : jusqu’où ces catalogues centralisés pourront-ils accompagner l’essor de la donnée et répondre aux nouveaux défis d’interopérabilité et de gouvernance à grande échelle ?
